
What is AWS S3?
Amazon S3 (Simple Storage Service) provides object storage, which is built for storing and recovering any amount of information or data from anywhere over the internet. It provides this storage through a web services interface. While designed for developers for easier web-scale computing, it provides 99.999999999 percent durability and 99.99 percent availability of objects. It can also store computer files up to 5 terabytes in size.
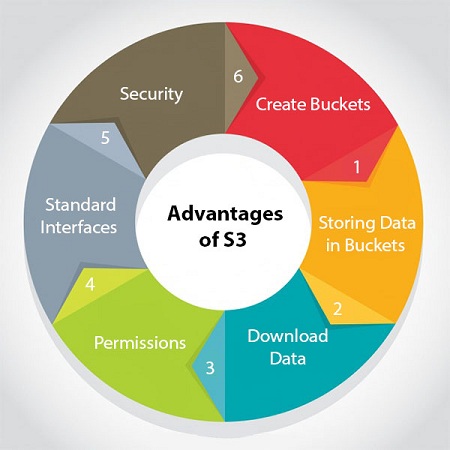
AWS S3 Benefits
Some of the benefits of AWS S3 are:
- Durability: S3 provides 99.999999999 percent durability.
- Low cost: S3 lets you store data in a range of “storage classes.” These classes are based on the frequency and immediacy you require in accessing files.
- Scalability: S3 charges you only for what resources you actually use, and there are no hidden fees or overage charges. You can scale your storage resources to easily meet your organization’s ever-changing demands.
- Availability: S3 offers 99.99 percent availability of objects
- Security: S3 offers an impressive range of access management tools and encryption features that provide top-notch security.
- Flexibility: S3 is ideal for a wide range of uses like data storage, data backup, software delivery, data archiving, disaster recovery, website hosting, mobile applications, IoT devices, and much more.
- Simple data transfer: You don’t have to be an IT genius to execute data transfers on S3. The service revolves around simplicity and ease of use.
These are compelling reasons to sign up for S3. Now, let’s move on and have a look at some of the major components of the AWS S3 storage service.
AWS Buckets and Objects
An object consists of data, key (assigned name), and metadata. A bucket is used to store objects. When data is added to a bucket, Amazon S3 creates a unique version ID and allocates it to the object.

Example of an object, bucket, and link address

Logging into AWS

Selecting S3 from Service offerings

Amazon S3 bucket list (usually empty for first-time users); create a bucket by clicking on the “Create bucket” button
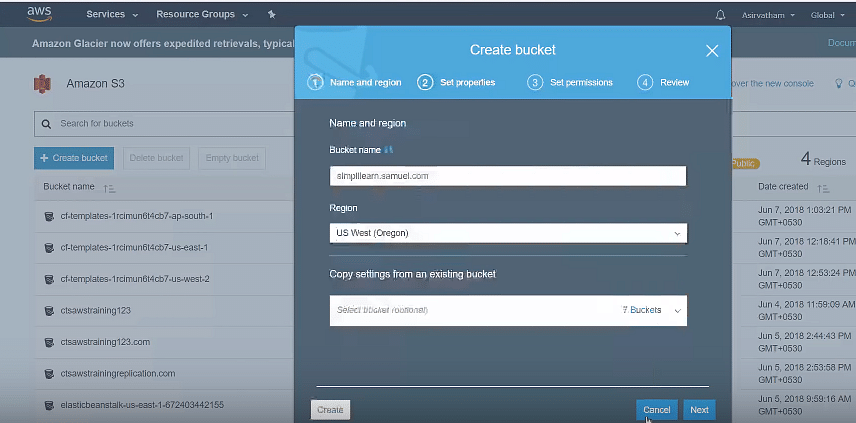
Create a bucket by setting up name, region, and other options; finish off the process by pressing the “Create” button
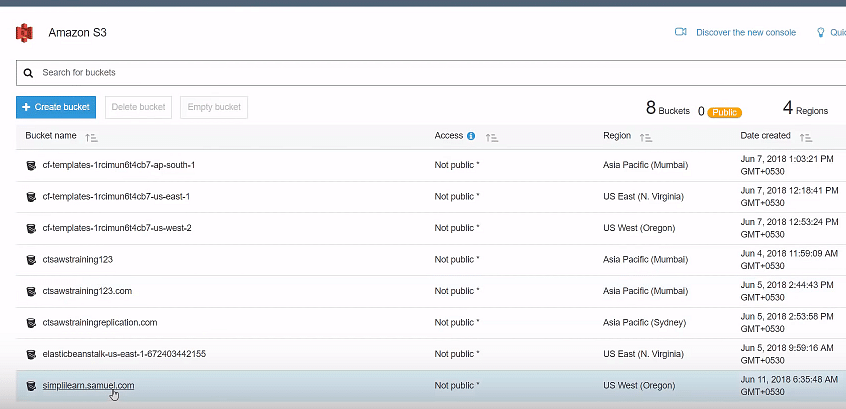
Select the created bucket

Click on upload to select a file to be added to the bucket
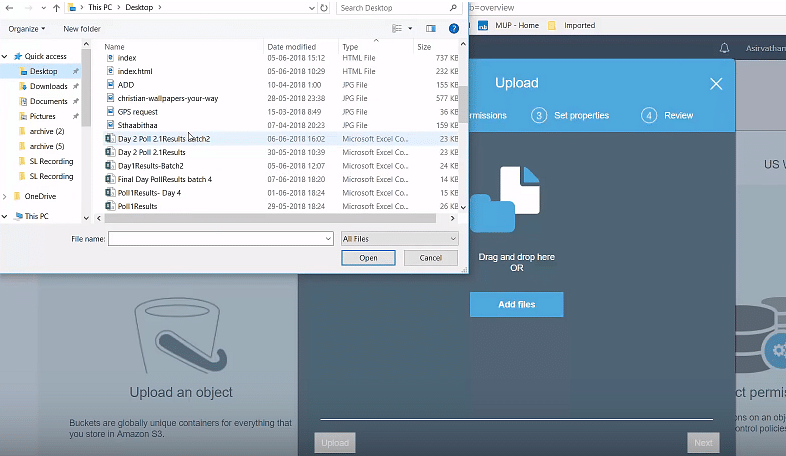
Select a file to be added
The file is now uploaded into the bucket
How Does Amazon S3 work?
Like we saw in the example above, first off, a user creates a bucket. When this bucket is created, the user will specify the region in which the bucket is deployed. Later, when files are uploaded to the bucket, the user will determine the type of S3 storage class to be used for those specific objects. After this, users can define features to the bucket, such as bucket policy, lifecycle policies, versioning control, etc.
Now, let’s talk about the different storage classes offered by Amazon S3.
What is AWS S3: Amazon S3 Storage Classes
Let’s have a look at the different storage classes using the example of a school:
Amazon S3 Standard for frequent data access: Suitable for a use case where the latency should below. Example: Frequently accessed data will be the data of students’ attendance, which should be retrieved quickly.
Amazon S3 Standard for infrequent data access: Can be used where the data is long-lived and less frequently accessed. Example: Students’ academic records will not be needed daily, but if they have any requirement, their details should be retrieved quickly.
Amazon Glacier: Can be used where the data has to be archived, and high performance is not required. Example: Ex-student’s old record (like admission fee) will not be needed daily, and even if it is necessary, low latency is not required.
One Zone-IA Storage Class: It can be used where the data is infrequently accessed and stored in a single region. Example: Student’s report card is not used daily and stored in a single availability region (i.e., school).
Amazon S3 Standard Reduced Redundancy storage: Suitable for a use case where the data is non-critical and reproduced quickly. Example: Books in the library are non-critical data and can be replaced if lost.

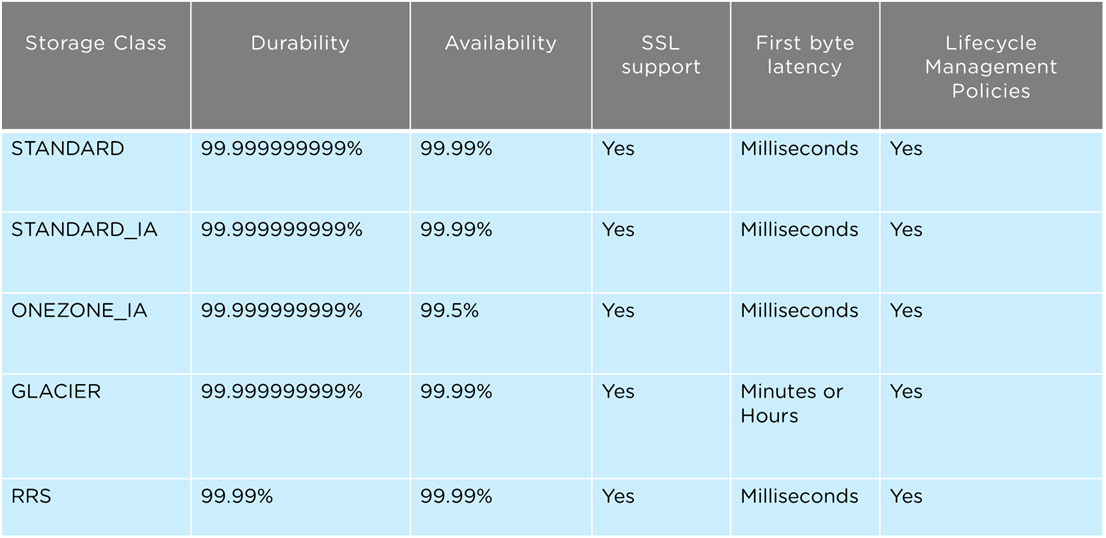
A comparison of all storage classes
AWS S3 Features
Lifecycle Management
In lifecycle management, Amazon S3 applies a set of rules that define the action to a group of objects. You can manage and store objects in a cost-effective manner. There are two types of actions:
1. Transition Action
With this action, you can choose to move objects to another storage class. With this, you can configure S3 to move your data between various storage classes on a defined schedule. Assume you’ve got some data stored in the S3 standard class. If this data is not used frequently for 30 days, it would be moved to the S3 infrequent access class. And after 60 days, it is moved to Glacier. This helps you to migrate your data to lower-cost storage as it ages automatically.
2. Expiration Actions
Here, S3 removes all objects within the bucket when a specified date or time period in the object’s lifetime is reached.An example of how lifecycle management works:
From within your bucket select management

Select “Lifecycle” and then click on the “Add lifecycle rule.”
Add a rule name and scope
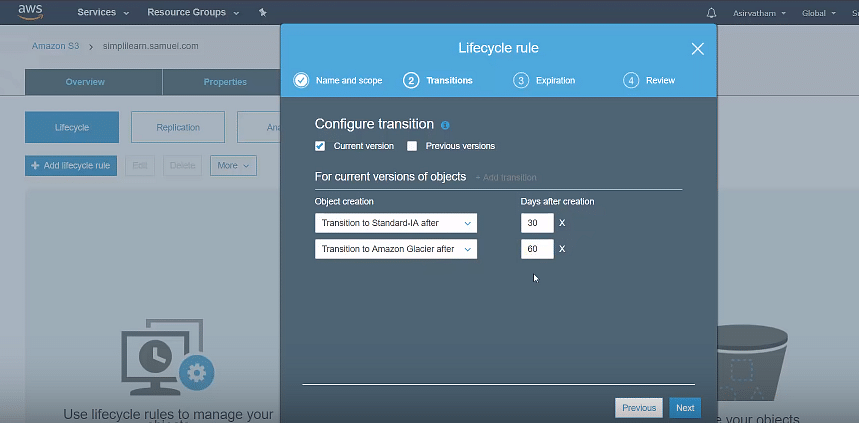
Configure transaction options
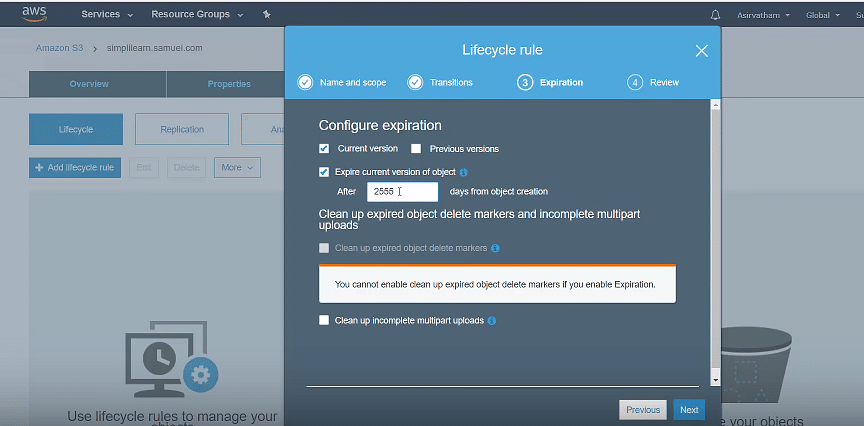
Set up expiration details
Bucket Policy
Bucket policy is an IAM policy where you can allow or deny permission to your Amazon S3 resources. With bucket policy, you also define security rules that apply to more than one file within a bucket. For example: If you do not want a user to access the “Simplilearn” bucket, then with the help of JSON script, you can set permissions. As a result, a user would be denied access to the bucket.
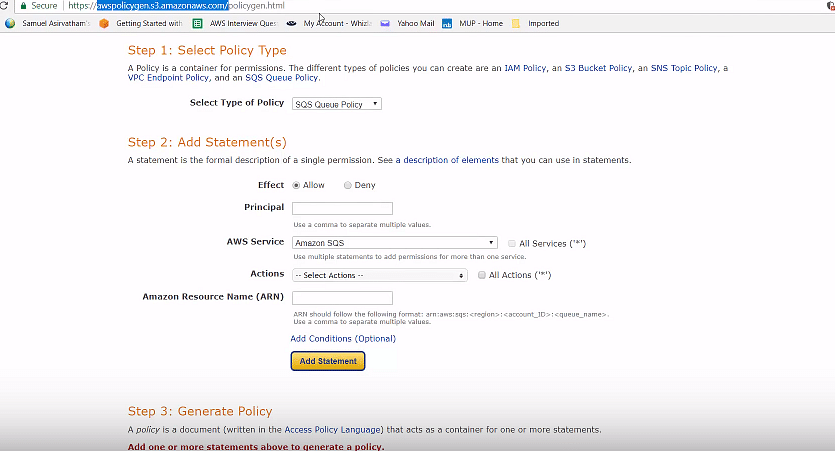
Use an online tool to generate a policy. Select the type of policy as an S3 bucket policy. Select the appropriate effect. In this case, denying access.

Find the ARN of the bucket
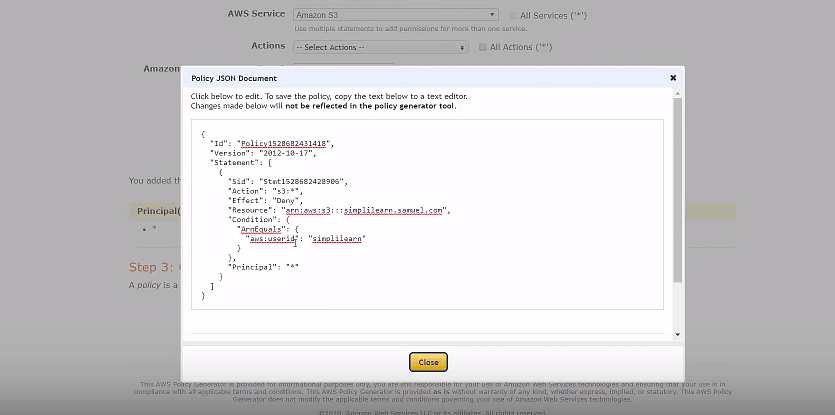
Set up additional conditions and set up a JSON script to deny access to a particular user. In this case, “simplilearn.”
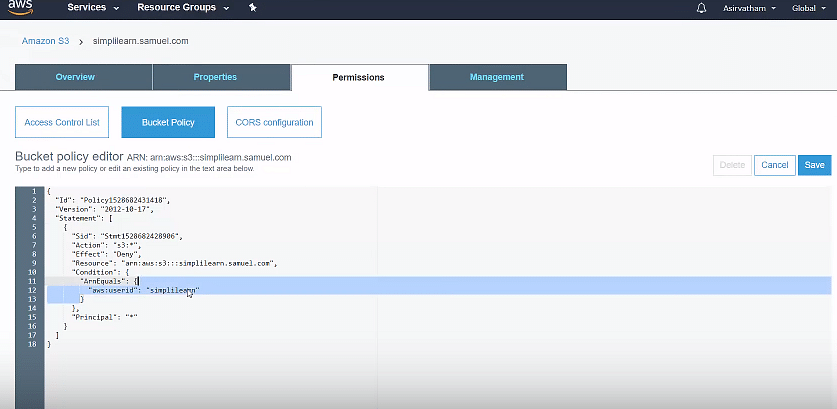
Go back to the bucket and set up a bucket policy under “Permissions.” Then click on “Save.”Amazon S3 protects your data using two methods:
Data encryption
- Versioning
- Cross-region Replication
- Transfer Acceleration
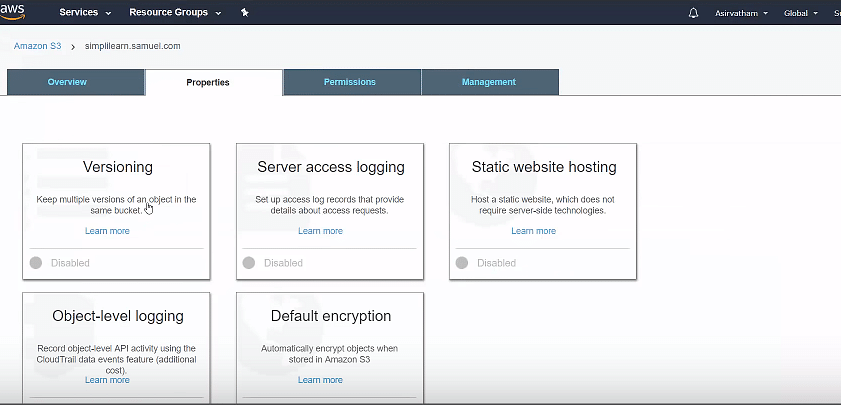
- Go to your bucket, select properties, and turn on “Versioning.”
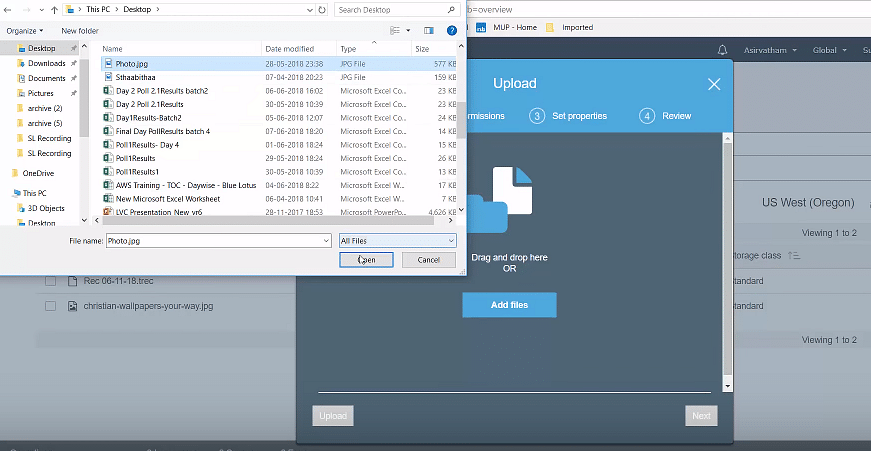
Upload an object

Upload another file of the same name

Select the file and alternate between its current and older versions
1. Data Encryption
This refers to the protection of data while it’s being transmitted and at rest. It can happen in two ways, client-side encryption (data encryption at rest) and server-side encryption (data encryption in motion).
2. Versioning
It is utilized to preserve, recover, and restore an early version of every object you store in your AWS S3 bucket. Unintentional erases or overwriting of objects can easily be managed with versioning. For example, in a bucket, it is possible to have objects with the same key name but different version IDs.
3. Cross-region Replication
Cross-region replication provides automatic copying of every object uploaded to your buckets (source and destination bucket) in different AWS regions. Versioning needs to be turned on to enable CRR.
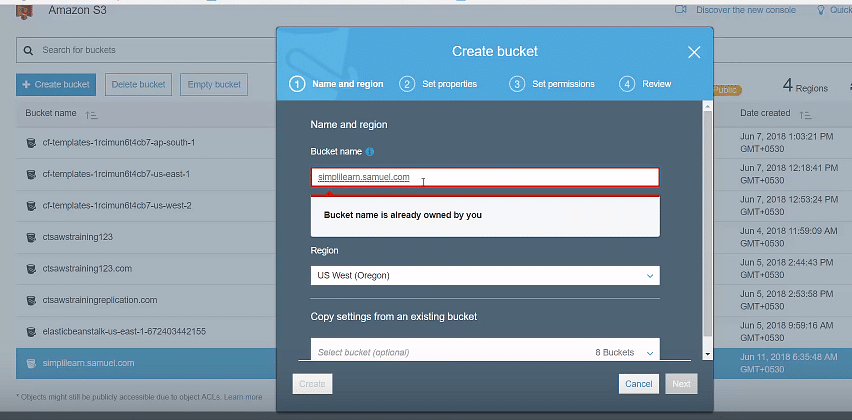
Create a new bucket in a different region
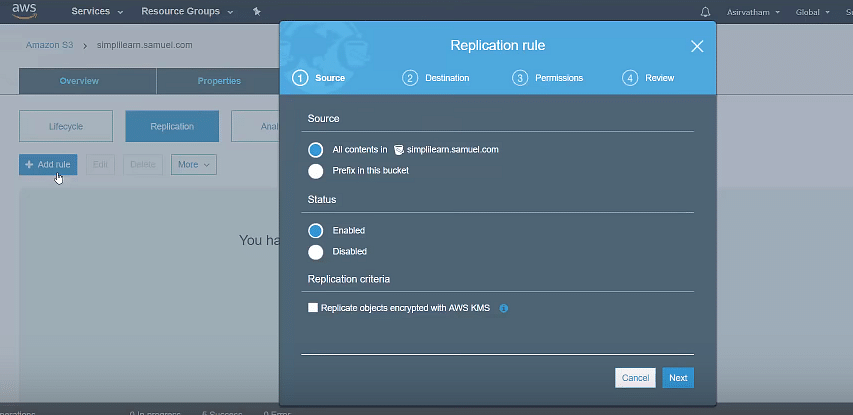
Select uploaded file, go to “Management” and then replication. Here, click on “Add Rule.”
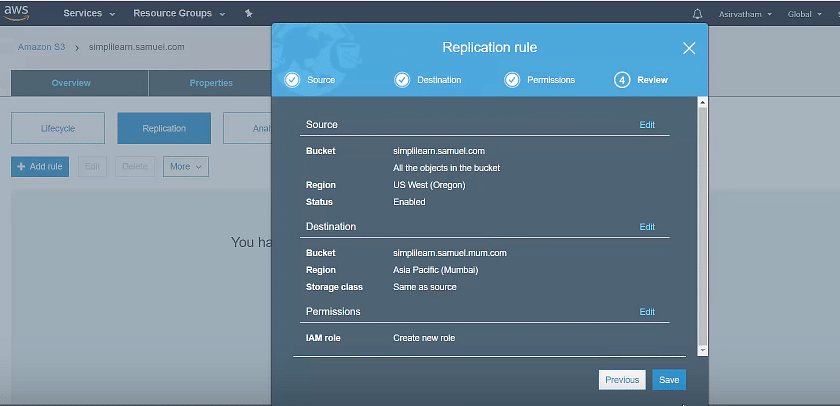
Select the source, destination, and IAM rule
4. Transfer Acceleration
This enables fast, easy, and secure transfers of files over long distances between your client and S3 bucket. The edge locations around the world provided by Amazon CloudFront are taken advantage of by transfer acceleration. It works by carrying data over an optimized network bridge that keeps running between the AWS Edge Location (closest region to your clients) and your Amazon S3 bucket.

Go to properties and select transfer acceleration to enable it
Amazon S3 Console
The Amazon S3 Console, found inside AWS Management, helps you to easily manage objects and buckets. The console gives users an intuitive, browser-based interface that lets you easily interact with AWS services.You use the S3 console to create, configure, and manage buckets, and to upload, download, and manage objects. The console also lets you organize storage using a logical hierarchy.
Competitor Services
AWS S3 isn’t the only object software storage service available. These are the primary competitive choices you can choose as alternatives:
Alibaba Cloud Object Storage Service (OSS)
Azure Blob storage
Cloudian
DigitalOcean Spaces
Google Cloud Storage
IBM Cloud Object Storage
Oracle Cloud Infrastructure Object Storage
Zadara Storage
Why Should I Consider Using Amazon S3?
Now that we’ve answered the question “What is AWS S3?” let’s dig into why you should consider using it. There are two big reasons why you should use Amazon S3, and they’re points we’ve covered before but bear calling further attention to:
S3 offers 99.999999999% (11 9s) data durability. That means, if you stored 10,000,000 objects in Amazon S3, you would only lose a single object every 10,000 years. That is durable!
S3 will automatically create and store copies of every uploaded object across many systems. This protects your data against errors, failures, and threats while guaranteeing you complete data availability when you need it.
Amazon Web Services is the most popular cloud provider available today.


{kind=link}